6.1. Architecture des services Web
6.1.1. Simple serveur statique
L’architecture la plus simple d’un service web consiste à avoir un simple serveur web hébergeant un ensemble de fichiers statiques constituant un site. Dans ce cas de figure, la question à se poser est de savoir où placer le serveur en question. S’il s’agit d’un site public, on le placera préférentiellement dans une zone dédiée isolée appelée zone démilitarisée (DMZ). La DMZ est un réseau séparé du réseau local interne par une couche de sécurisation supplémentaire (firewall au minimum). Ce réseau séparé permet d’éviter d’exposer le réseau et les services internes directement au traffic internet auquel ils n’ont pas nécessité d’être exposé. Par contre, on placera dans la DMZ tous les services accessibles publiquement, c’est à dire les services acceptant des requêtes (en pratique, des demandes de connexion TCP) venant d’adresses IP externes.
Assez logiquement, dans le cas d’un site web interne qui ne reçoit des requêtes qu’en provenance d’adresses IP internes, ce dernier ne sera pas placé en DMZ mais plutôt dans une zone dédiée aux services internes (appelée par ex. Trusted Zone), elle aussi protégée par une couche de sécurité permettant d’empêcher l’accès depuis internet et de limiter et contrôler l’accès depuis les postes client internes.
6.1.2. Site dynamique et base de données
Si le site souhaité est un site dynamique, il faudra lui adjoindre une base de données. On pourrait héberger cette base de données sur la même machine que le serveur web, mais ce n’est pas une bonne pratique : En effet, la base de données contient souvent des données essentielles, et doit être soigneusement sécurisée. Il est ainsi par exemple essentiel de ne jamais rendre une base de données accessible depuis l’extérieur! Une base de données n’a donc normalement pas sa place en DMZ.
Plusieurs options sont possibles :
- Connecter la base de données sur une autre interface réseau du serveur Web, formant ainsi un réseau point-à-point dédié. Cette solution peut convenir si le serveur est le seul à devoir accéder à la base de données. Néanmoins, en cas de compromission du serveur web, la base de données devient une cible facile, car il n’y a pas de device intermédiaire de surveillance (pare-feu).
- Si plusieurs serveurs doivent accéder à la DB, venant de différentes zones (DMZ, Trusted Zone, …), il importe d’isoler la DB dans une zone séparée, avec des pare-feux adéquat. En effet, on ne peut pas la mettre en DMZ. Ce n’est pas non plus une bonne idée de la mettre en Trusted Zone, car cette dernière recevrait alors du trafic en provenance de la DMZ, donc potentiellement dangereux.
Dans tous les cas, il importe de sécuriser soigneusement la communication serveur web / DB au niveau du serveur DB (SGBD) :
- Créer un utilisateur non privilégié utilisé par le serveur web
- Configurer les permissions d’accès à la DB pour l’utilisateur non privilégié (interdire les opérations telles que les “DROP TABLE”, et réfléchir au cas par cas à l’accès à chaque table (SELECT/UPDATE/…)
- Configurer un contrôle d’accès sur base de l’IP pour la connexion à la DB (n’autoriser que le serveur Web pour l’utilisateur créé)
6.1.3. Répartition de charge
Si la charge augmente sur un serveur web et qu’on désire le soulager en le dédoublant, il faut trouver un moyen de répartir les requêtes HTTP entre les deux serveurs. Pour cela, deux options sont possibles :
- Utiliser le DNS et donner deux enregistrement A ou AAAA pour le site concerné . En fonction de la réponse du DNS, les clients interrogeront l’un ou l’autre serveur. Bien que facile à mettre en oeuvre, cette solution a l’inconvénient de ne pas être finement configurable afin de s’adapter aux variations de charge.
- Utiliser un appareil intermédiaire en première ligne, qui se charge alors de rediriger les requêtes vers l’un ou l’autre serveur web, en fonction de leurs charges respectives. Cet appareil tient le rôle de répartiteur de charge / load balancer. Il peut être contrôlé plus facilement que le DNS pour s’adapter aux variations de charge sur les serveurs.

6.1.4. Reverse Proxy et Proxy
L’idée de placer un device devant un ou plusieurs serveurs web peut être généralisée au delà du besoin de répartition de charge. Un appareil placé devant des serveurs web et “interceptant” les requêtes HTTP avant de les transmettre aux serveurs s’appelle un Reverse Proxy. Il peut fournir plusieurs rôles afin notamment de soulager la charge de calcul des serveurs web :
- Répartiteur de charge, comme mentionné plus haut
- Accélérateur HTTP : En utilisant une cache pour les objets statiques (images, fichiers js, …), il permet de diminuer la charge sur les serveurs HTTP.
- Terminateur HTTPS : Il peut se charger de tout ce qui est négociation TLS et chiffrement/déchiffrement des données, avant de transmettre les requêtes HTTP en clair aux serveurs web.
- Compression : il peut réduire la taille des données des payloads HTTP en appliquant des algorithmes de compression
- Sécurité : Il peut filtrer les requêtes reçues et supprimer les requêtes suspicieuses pour éviter de compromettre les serveurs
- Gestion de sites multiples : Si plusieurs sites doivent être accessibles sur l’IP publique, et sont hébergés par des serveurs différents, le reverse proxy peut se charger de rediriger la requête vers le bon serveur.
La figure ci-dessous illustre le positionnement d’un Reverse Proxy dans un réseau utilisant plusieurs serveurs Web. Comme le Reverse Proxy est le serveur qui reçoit les données venant d’Internet, il doit logiquement se placer en DMZ. Les serveurs Web peuvent alors être placés dans une autre zone séparée, avec un firewall surveillant le traffic depuis le Reverse Proxy. Attention : les serveurs web ne sont pas pour autant à placer avec les serveurs internes : ils reçoivent tout de même du trafic en provenance indirect d’Internet.
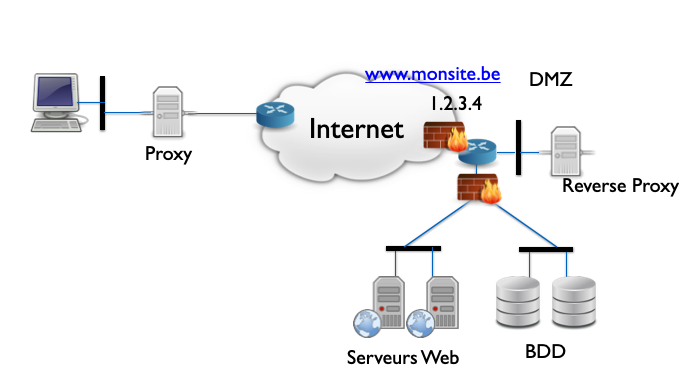
La figure ci-dessus illustre également la notion de Proxy HTTP. Contrairement à un Reverse Proxy HTTP qui se place devant un ou plusieurs serveurs, un Proxy HTTP se place devant un client Web.
Un Proxy HTTP va recevoir et relayer les requêtes HTTP générées par le client. Plusieurs usages sont possibles de ce mécanisme. Ainsi, en entreprise, un Proxy Web permettra :
- d’optimiser les performances de la navigation des employés via un mécanisme de cache des ressources web
- de logger et analyser les requêtes à des fins de monitoring
- de filtrer et limiter l’accès à certains contenus
- ..
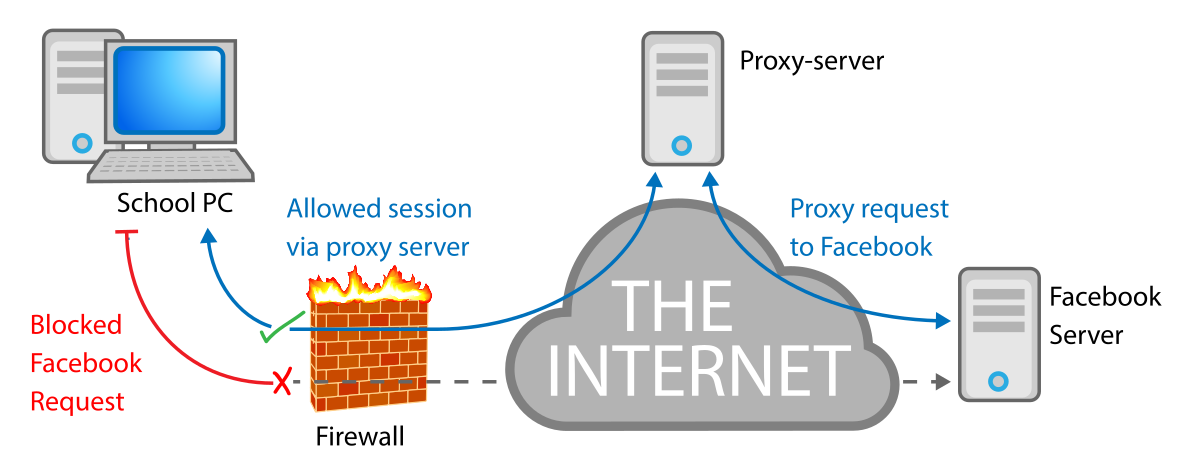
Un proxy peut également être utilisé par des postes clients pour contourner des restrictions d’accès. Par exemple, un proxy extérieur peut être utilisé pour accéder à un site interdit dans le réseau où se situe le client. Dans l’exemple ci-dessous, le firewall bloque l’accès à Facebook, mais pas au serveur proxy, qui peut ainsi donner un accès indirect au réseau social.